



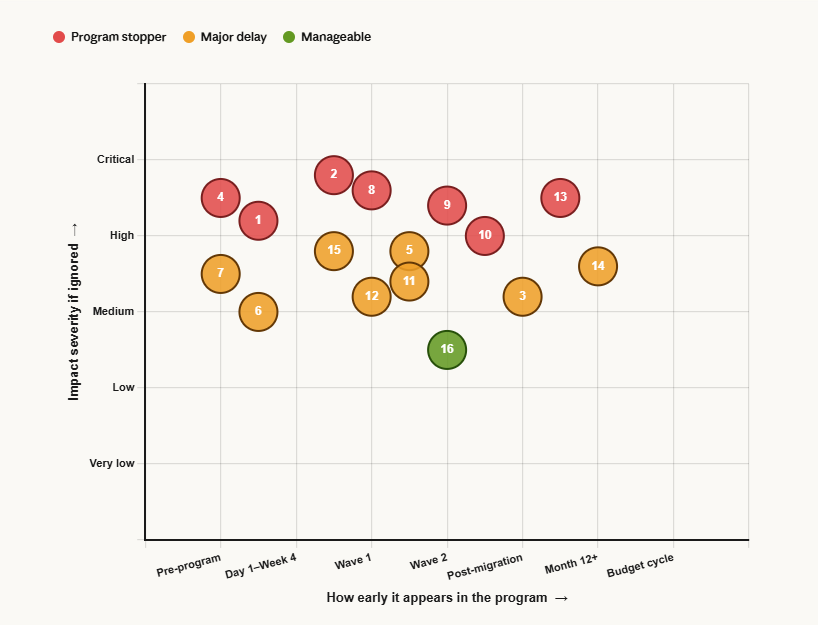
1.Practical Realities of Application Rationalization & Modernization
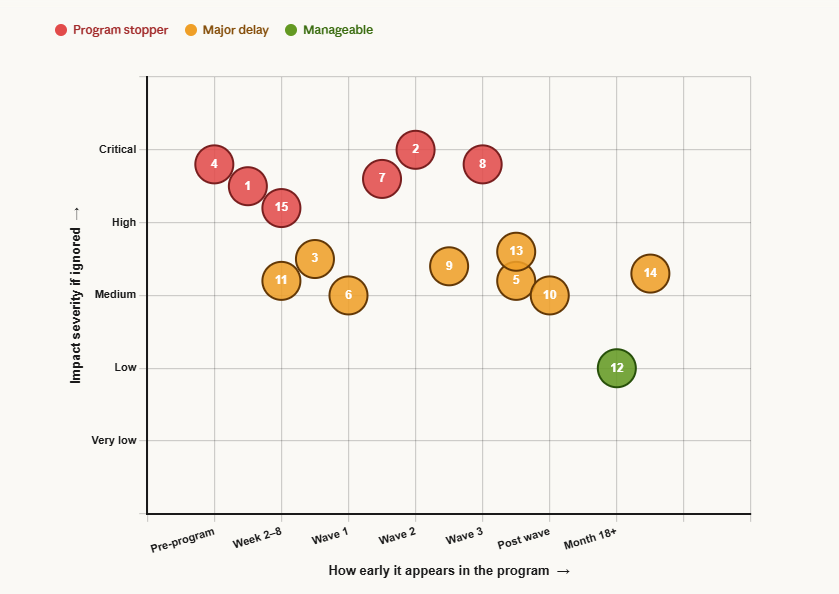
15 ground-level realities every program encounters — classified by when they surface and impact if ignored
Program stopper
Major delay
Manageable
Application rationalization programs routinely underdeliver — not because the strategy is wrong, but because the ground rarely resembles the plan. Portfolios are larger than any CMDB admits. Data migrations outlast the applications they support. Business resistance is structural, not personal. Costs run two to three times estimates before the first wave completes. These are not edge cases or execution failures — they are the predictable, recurring conditions that define how rationalization programs actually behave in practice. Understanding them before the program begins is the single most reliable way to close the gap between what the business case promises and what the program delivers.
Showing 15 of 15 realities
Reality · Surfaces at · Severity
Key observations
01Portfolio Discovery Is Always Worse Than Expected
- Most organizations underestimate their portfolio by 30–40% — shadow IT, forgotten apps, and undocumented systems surface mid-program
- Application inventories in CMDBs are typically 60–70% accurate at best
- Many apps have no clear owner, documentation, or known user base
- “Zombie apps” (running but unused) consume 15–25% of maintenance budgets silently
02Data Is the Real Blocker
- Applications can be decommissioned in weeks; migrating or archiving their data takes months
- Regulatory retention requirements (GDPR, HIPAA, SOX) force data preservation even after app retirement
- Data quality is almost always poor — duplicates, orphaned records, inconsistent schemas
- Many legacy apps are the only system of record for critical historical data
03Business Resistance Is Structural, Not Personal
- Business users have built workarounds, macros, and muscle memory around legacy systems over years
- “We only use 20% of the features but that 20% is mission-critical” is universally true
- Every app has at least one power user who will escalate to leadership if threatened
- Rationalization is perceived as IT taking something away, not delivering value
04Costs Are Always Underestimated
- Migration costs routinely run 2–3x original estimates
- Dual-running costs (old + new system simultaneously) are rarely budgeted for
- Change management and training costs are the most commonly omitted line items
- Integration remediation after decommission typically costs more than the decommission itself
05Savings Take Longer to Materialize
- Licenses and maintenance contracts have termination clauses — savings aren’t immediate
- Infrastructure costs don’t reduce until hardware is physically decommissioned or cloud instances terminated
- FTE savings require headcount decisions that are politically difficult
- Expected savings of Year 1 typically land in Year 2 or Year 3
06Vendor Contracts Create Unexpected Friction
- Multi-year SaaS contracts continue billing even after migration away from the platform
- Enterprise software vendors (Oracle, SAP, IBM) use audits strategically to slow transitions
- “True-up” clauses in license agreements can generate surprise invoices mid-program
- Maintenance contracts often cannot be partially cancelled — it’s all or nothing
07The “One More Release” Trap Is Endless
- Legacy applications are perpetually kept alive by promises of a final enhancement before retirement
- Business units negotiate “just one more feature” that delays decommission by 6–12 months repeatedly
- Development teams assigned to migration get pulled back to maintain legacy systems during transition
- Every release of a legacy app increases the migration complexity and cost of the eventual replacement
- Programs without hard sunset dates almost never achieve decommission — deadlines must be non-negotiable
08Compliance and Audit Requirements Create Unexpected Anchors
- Regulatory bodies (SEC, FDA, FCA) may require applications to remain accessible for 7–10 years post-decommission
- Audit trails embedded in legacy applications cannot always be exported to modern formats
- SOX-controlled applications require documented evidence of access controls throughout transition periods
- Healthcare applications under HIPAA require validated systems — revalidation of replacements adds 3–6 months
- Compliance teams are rarely engaged early enough, discovering blockers only when decommission is imminent
09Organizational Restructures Reset Program Progress
- Mergers, acquisitions, and divestitures fundamentally change portfolio scope mid-program
- Leadership changes bring new priorities — rationalization programs lose executive sponsors regularly
- Business unit reorganizations orphan applications whose owning teams no longer exist
- Post-merger portfolio integration doubles complexity — two inventories, two governance models, two vendor landscapes
- Programs typically lose 3–6 months of momentum after every significant organizational change
10Cloud Migration Does Not Automatically Mean Rationalization
- “Lift and shift” migrations move legacy problems to the cloud without resolving them
- Cloud-hosted legacy applications often cost more than their on-premises equivalents initially
- Organizations declare victory at infrastructure migration while application debt remains entirely unaddressed
- Cloud environments create new shadow IT — teams spin up unauthorized instances and services rapidly
- True rationalization requires application-layer decisions, not just infrastructure-layer migrations
11Vendor Managed Services Create Hidden Lock-In
- Outsourced application management contracts include penalties for early termination that exceed rationalization savings
- Managed service providers have commercial incentives to keep application portfolios large and complex
- SLAs in outsourcing contracts are written around existing applications — decommissions require contract renegotiation
- Vendors controlling legacy environments slow-walk transitions to protect their revenue streams
- Insourcing knowledge before decommission is essential but chronically underbudgeted in program plans
12Integration Middleware Becomes the Last Man Standing
- After applications are decommissioned, their integration middleware (MuleSoft, IBM MQ, TIBCO) often remains active
- Orphaned message queues and API endpoints continue running — consuming cost and creating security exposure
- Integration platforms accumulate technical debt independently of the applications they connect
- Decommissioning the middleware layer requires a separate program effort that is rarely planned for upfront
- Integration cleanup typically adds 20–30% to total program duration after application decommissions complete
13Security Vulnerabilities Accelerate But Also Complicate Decisions
- Unpatched legacy applications create pressure to decommission faster than the business is ready to transition
- Security teams issue mandates to retire vulnerable systems on timelines that ignore migration complexity
- Zero-day vulnerabilities in legacy platforms force emergency decisions without proper business impact assessment
- Compensating controls (network segmentation, WAF rules) become permanent workarounds instead of temporary bridges
- Security-driven decommissions bypass governance processes and frequently result in poor replacement decisions made under pressure
14Program Fatigue Sets In After 18–24 Months
- Stakeholders disengage from rationalization programs that run longer than two years without visible results
- Business units stop cooperating with assessments and interviews as program timelines extend
- Executive attention shifts to newer strategic priorities — rationalization loses its urgency narrative
- Program teams experience high turnover after 18 months, losing institutional knowledge mid-execution
- Breaking large programs into 12-month phases with discrete outcomes maintains momentum far more effectively than single multi-year programs
15Technical Documentation Almost Never Exists
- Application architecture documents, data dictionaries, and integration specifications are missing for 60–80% of legacy applications
- Tribal knowledge concentrated in 1–2 individuals becomes a single point of failure for the entire decommission
- Reverse engineering legacy code to understand business logic adds 2–4 months per complex application
- Database schemas contain decades of accumulated logic in stored procedures, triggers, and views that are undocumented
- Knowledge capture must be treated as a formal program deliverable — not assumed to happen organically during migration
2.Implementation Challenges in Application Rationalization & Modernization
16 blockers that stall, derail, or kill rationalization programs — with root causes and impact
Implementation challenges in rationalization programs rarely announce themselves early. They surface mid-execution — after timelines are committed, funding is approved, and business expectations are set. Ownership gaps, dependency complexity, governance failures, and budget reforecasting are not surprises to those who have run these programs before. They are predictable, recurring structural problems that require deliberate mitigation before execution begins, not reactive firefighting after they ignite.
Showing 16 of 16 challenges
Challenge · Core problem · Impact
Key observations
Program stopper
01Application Ownership Gaps
- IT owns the infrastructure but not the business process
- Original developers have left; no institutional knowledge remains
- Multiple departments claim partial ownership, creating decision paralysis
Program stopper
02Dependency Mapping Complexity
- Decommissioning one app breaks three others unexpectedly
- API dependencies are rarely documented in any CMDB or architecture repository
- Batch file transfers between systems are invisible to standard discovery tools
- Database-level integrations (shared tables, direct DB links) are hardest to detect
Major delay
03Technical Debt Inheritance
- Data models built for 2005 business logic don’t map cleanly to modern SaaS schemas
- Custom fields, custom workflows, and custom reports must be rebuilt from scratch
- Integrations rebuilt for the new platform often recreate old anti-patterns
- “Lift and shift” migrations defer rather than eliminate technical debt
Program stopper
04Governance and Decision Authority
- CIO authority stops at IT infrastructure; business application decisions require business sign-off
- Federated IT models mean each business unit has veto power over their apps
- Legal, compliance, and finance all have independent approval gates with no coordination
- Program governance committees meet quarterly; programs need weekly decisions
Major delay
05Scope Creep and Feature Parity Trap
- Business units demand 100% feature parity before migration, including features nobody uses
- “While we’re at it” requests add new requirements to migration projects
- Custom reports built on legacy systems require months of rebuild effort
- The target state keeps moving as the program progresses
Major delay
06Talent and Skill Gaps
- COBOL, PowerBuilder, and classic ASP developers are scarce and expensive
- Cloud-native architects don’t understand legacy business logic encoded in old systems
- Knowledge transfer from legacy experts to modern platform teams is chronically underfunded
- Vendor-certified talent for target platforms (Salesforce, Workday, ServiceNow) commands significant premiums
Major delay
07Measurement and Baseline Problems
- Total cost of ownership per application is rarely known — it must be constructed
- Shared infrastructure costs are difficult to allocate per application
- FTE effort per application is estimated, not measured
- Without a baseline, program ROI becomes a credibility battle with Finance
Program stopper
08Application Interdependency With Business Processes
- SOPs, training manuals, and audit documentation all reference specific application screens and workflows
- Operational teams build compensating manual processes around application limitations that become invisible dependencies
- Regulatory submissions and external reporting reference specific application outputs — format changes require regulator notification
- Process mining tools (Celonis, UiPath Process Mining) are rarely used upfront, leaving process dependencies undiscovered until cutover
Program stopper
09Data Archival and Retrieval Complexity
- Active, historical, and audit data have different retention rules that rarely align with decommission timelines
- Legacy data formats (EBCDIC, fixed-width flat files, proprietary binary) require specialized tooling to extract
- Business users demand ad-hoc retrieval years after decommission — with no agreed SLA or tooling
- Legal holds can freeze decommission of specific application data indefinitely with no advance warning
- Cloud archival (AWS Glacier, Azure Archive) is cheap for storage but expensive and slow for retrieval at scale
Program stopper
10Testing Coverage Gaps in Legacy Systems
- Regression test suites are largely manual, undocumented, and dependent on institutional knowledge
- Business acceptance testing is performed by users who no longer fully understand the system
- Performance and load testing is rarely conducted at production scale during migration validation
- Test environments for legacy systems are frequently out of sync with production
- Building retroactive test coverage adds 3–6 months but is rarely prioritized or funded
Major delay
11Multi-Vendor Coordination Failures
- Legacy vendors deliberately delay data exports and API documentation to protect revenue
- Replacement vendors overpromise migration support and underdeliver once contracts are signed
- System integrators have no contractual accountability for post-migration business outcomes
- Coordinating delivery across time zones, contract boundaries, and hierarchies requires dedicated vendor management rarely staffed
Major delay
12Identity and Access Management Across Transitioning Systems
- Legacy applications use local user databases, shared service accounts, and hardcoded credentials incompatible with modern SSO
- Service accounts embedded in integrations are undocumented and discovered only when decommission breaks downstream processes
- Privileged access reviews surface compliance violations that create legal exposure mid-program
- Audit evidence of access controls must be maintained across both legacy and replacement systems during parallel running
Program stopper
13Budget Reforecasting Mid-Program
- Annual budget cycles do not align with multi-year funding requirements — Year 1 approvals don’t guarantee Year 2
- CFO changes, economic downturns, and competing priorities trigger mid-program budget cuts
- Contingency budgets are routinely stripped during approval, leaving zero tolerance for inevitable scope changes
- Savings realized in early phases are frequently reclaimed by Finance before reinvestment into later phases
- Programs unable to demonstrate ROI within 12 months are disproportionately targeted for reduction
Major delay
14Change Fatigue Across Simultaneous Transformation Programs
- Business units absorbing ERP upgrades, cloud migrations, and restructures have no remaining capacity for rationalization
- End users experiencing multiple system changes within 12 months disengage from all programs
- Training capacity is finite — simultaneous platform transitions cannot all be supported at once
- IT teams supporting parallel programs make sequencing errors — infrastructure decommissioned before dependent migrations complete
- Change impact assessments in isolation per program miss cumulative disruption to the same user populations
Major delay
15Contractual Obligations With Embedded Application Logic
- Customer contracts specify report formats, data delivery methods, and system interfaces tied to legacy outputs
- EDI connections with suppliers reference specific transaction formats generated by legacy systems
- Regulatory submissions accepted in legacy formats may not be accepted from replacement platforms without pre-approval
- SLA commitments based on legacy system performance must be matched or exceeded from Day 1 on replacements
- Renegotiating contracts adds legal and commercial complexity entirely outside IT’s control
Manageable
16Embedded Reporting and Analytics Dependencies
- Executive dashboards and regulatory filings pull directly from legacy databases via hardcoded SQL queries
- Hundreds of operational reports (Crystal Reports, SSRS) depend on legacy data models absent from replacement platforms
- Data warehouses built incrementally on legacy source systems break entire analytics pipelines when schemas change
- Business users treat reports as more critical than the applications generating the underlying data
- Self-service tools (Tableau, Power BI) connected directly to legacy databases create ungoverned dependencies invisible to IT
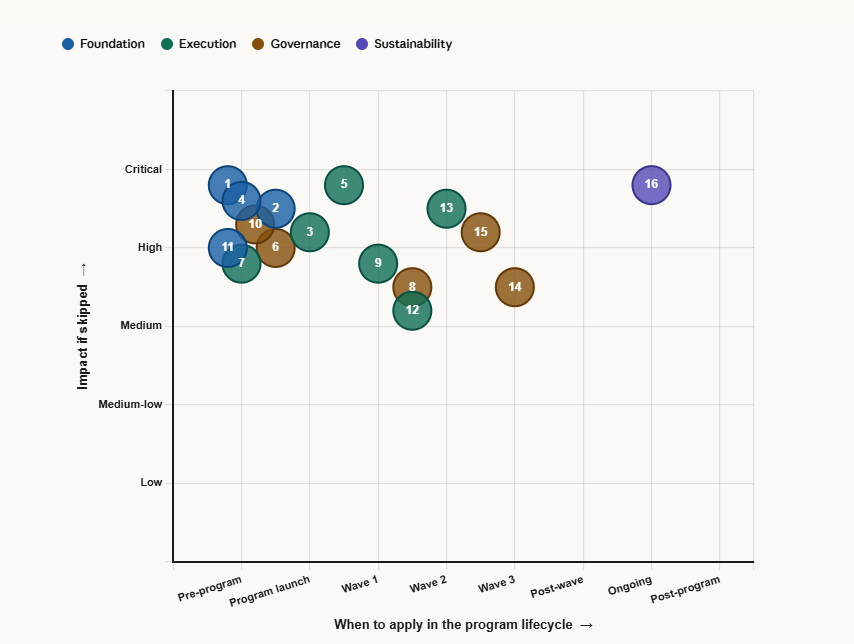
3.Approaches That Work in Application Rationalization & Modernization
16 practitioner-proven approaches — grouped by program phase
Successful rationalization programs are not defined by the quality of their frameworks — they are defined by the discipline of their execution. The approaches below are not theoretical best practices. They are the specific interventions that separate programs that deliver from programs that stall. Each is sequenced against a program phase: foundation work that must precede execution, execution disciplines that sustain momentum, governance structures that protect the program, and sustainability practices that prevent the debt from returning.
Showing 16 of 16 approaches
Approach · Phase · When to apply
Key actions
Foundation
01Start With a Current State Assessment, Not a Business Case
- Build the application inventory first — before committing to savings targets
- Use automated discovery tools (ServiceNow, Flexera, RISC Networks) alongside manual interviews
- Establish cost-per-application baseline using fully-loaded TCO (infra + licenses + FTE + vendor + integration)
- Classify every app by Business Criticality / Technical Health / Usage / Ownership before making any decisions
Foundation
02Implement a Tiered Decision Framework (5R or 7R Model)
- Retire (15–25%): zero/low usage, process discontinued
- Replace (25–35%): COTS covers ≥80% of requirements
- Consolidate (10–20%): duplicate functionality across business units
- Refactor (5–10%): high value, poor technical foundation — apply selectively
- Rehost/Replatform (5–15%): cloud migration with minimal or minor code change
Execution
03Sequence for Momentum, Not Just Savings
- Wave 1: pure retirements — lowest effort, fastest wins, builds organizational credibility
- Wave 2: simple replacements — well-defined COTS alternatives, willing business owners
- Wave 3: consolidations — require more coordination but deliver the largest savings
- Wave 4: refactors — longest lead time, highest complexity, reserved for strategic platforms
Foundation
04Assign Application Business Owners, Not IT Owners
- Every application must have a named business executive as accountable owner — not an IT product manager
- Business owner signs off on retirement decisions; IT does not unilaterally decommission
- Create an Application Portfolio Review Board with business unit representation at VP level or above
- Tie application ownership to chargeback — ownership must carry financial consequences to drive decisions
Execution
05Dependency Mapping Before Any Decommission
- Run network traffic analysis (Dynatrace, AppDynamics, AWS X-Ray) to map live integrations before touching anything
- Conduct structured interviews with integration, middleware, and database teams — tools miss what people know
- Map database-level dependencies using schema analysis tools — shared tables and direct DB links are hardest to find
- Maintain a live dependency register and update it before every wave — dependencies change as programs progress
Governance
06Ring-Fence Savings Immediately
- Establish a dedicated rationalization program fund at launch — agreed with CFO, not just CIO
- Work with Finance to formally retire budget lines the moment applications are decommissioned
- Terminate licenses and maintenance contracts the moment migration is confirmed — not at contract renewal
- Track realized vs. projected savings monthly and publish results to executives — visibility protects the fund
Execution
07Manage Business Change as a Program Workstream, Not an Afterthought
- Embed a dedicated Change Manager in the program team from Day 1 — not a part-time role
- Communicate decommission timelines 90–180 days in advance — surprises create resistance that delays cost months
- Provide parallel running periods — never hard-cutover without user validation and confirmed adoption
- Build a formal hypercare model post-migration: minimum 30–60 days of dedicated transition support per application
Governance
08Use a Portfolio Heatmap for Ongoing Governance
- Plot every application on Business Value (Y) vs. Technical Health (X) — updated quarterly
- High value + low health → Invest (Refactor/Replace); Low value + low health → Eliminate (Retire/Consolidate)
- Low value + high health → Migrate (Rehost/Replatform); High value + high health → Tolerate (Retain/Monitor)
- Use heatmap position to sequence waves — the Eliminate quadrant is always Wave 1
Execution
09Measure What Matters and Report Monthly
- Applications decommissioned — cumulative count vs. plan (the headline metric)
- Annual run cost eliminated — $ vs. baseline; realized savings not projected
- Licenses terminated — count and $ value; validates vendor contract savings
- Portfolio size reduction — % reduction from baseline; the strategic KPI
- Realized savings vs. projected — variance %; the CFO’s primary question
Governance
10Establish a Dedicated Application Rationalization Office (ARO)
- Staff with business analysts, enterprise architects, financial analysts, and change managers — not purely IT PMs
- Give the ARO formal authority to escalate stalled decisions to CIO and business unit executives
- Embed ARO liaisons within each major business unit — decisions made closer to the business move faster
- Publish a monthly Portfolio Health Report to all senior stakeholders — visibility creates accountability
- Transition ARO from program execution to permanent governance after waves complete
Foundation
11Implement APM Tooling From Day One
- Deploy LeanIX, Apptio, ServiceNow SPM, or Planview before assessment — never start in Excel
- Integrate APM with CMDB, financial systems, and HR directories to auto-populate cost and ownership data
- Use APM dashboards as the single source of truth — never allow parallel shadow tracking in spreadsheets
- Make APM dashboards accessible to business stakeholders — portfolio visibility drives business-led decisions
- Assign data stewards per application category with monthly accuracy reviews — governance prevents data decay
Execution
12Run Continuous Usage Analytics, Not Point-in-Time Assessments
- Deploy usage monitoring (Pendo, WalkMe, Nexthink, ControlUp) to capture real behavioral data — not self-reported usage
- Identify unused features within retained applications — partial rationalization reduces complexity without full decommission
- Set a usage threshold policy: applications below defined thresholds enter automatic retirement review
- Monitor trends over 6–12 months — seasonal patterns make low-usage apps appear redundant when they are not
- Share usage dashboards with business owners quarterly — self-service data prompts voluntary rationalization conversations
Execution
13Build a Formal Knowledge Capture Program Before Any Decommission
- Treat knowledge capture as a mandatory program gate — no decommission proceeds without completed transfer documentation
- Document business rules encoded in application logic, not just technical specs — business logic is what gets lost permanently
- Create runbooks covering integration touchpoints, batch schedules, exception handling, and manual workarounds in place
- Record video walkthroughs of key workflows — video captures nuance that written documentation consistently misses
- Store in a searchable, version-controlled repository (Confluence, Notion) — not email threads or shared drives
Governance
14Use Architectural Fitness Functions to Prevent Future Portfolio Debt
- Define measurable architectural standards every application must meet — stack currency, security, integration patterns, observability
- Automate fitness checks using SonarQube, Snyk, Backstage, Checkov — manual compliance reviews drift and fail
- Every new application entering the portfolio must pass fitness gates before approval — prevention before debt accumulates
- Applications failing fitness functions enter an automatic remediation queue — non-compliance is never an indefinite status
- Publish fitness function results in the ARO’s monthly Portfolio Health Report — technical health visible to business and finance
Governance
15Implement Parallel Running Governance With Hard Cutoff Dates
- Define parallel running periods contractually before each wave — open-ended running must never be the default
- Set hard cutover dates 90 days after go-live as standard — extensions require executive-level formal approval
- Charge business units explicitly for dual-running costs in chargeback — financial visibility accelerates cutover decisions
- Conduct weekly reviews tracking issue count, severity trend, adoption rate, and outstanding blockers
- Publish a parallel running cost clock visible to stakeholders — cost visibility outperforms milestone dashboards every time
Sustainability
16Treat Rationalization as a Continuous Discipline, Not a One-Time Program
- Embed rationalization reviews into the annual IT planning cycle — every application assessed annually against current business value
- Make new application approval a governed process — every addition requires a formal business case and ARO sign-off
- Establish a Technology Radar — technologies classified as Hold trigger automatic rationalization reviews for dependent applications
- Tie enterprise architecture review board approvals to portfolio rationalization commitments — new investment conditional on legacy retirement plans
- Cultural shift is the ultimate measure: rationalization becomes how the organization manages technology, not a periodic crisis response
Success Factors, Failure Reasons & Risks
Application Rationalization & Modernization Programs — Top 10 each
Top 10 Reasons for Success
Showing 10 of 10 success factors
Factor · Category
Key observations
People & Ownership
01Unwavering Executive Sponsorship With Decision Authority
- Sponsors actively participate in monthly steering committees — not just kick-off presentations
- Executive sponsors personally resolve business unit escalations within 48 hours
- Dual CIO/CFO sponsorship achieves 40% faster decommission rates than IT-only sponsored programs
- Sponsor continuity matters as much as seniority — losing a sponsor mid-execution costs 6 months on average
Process & Execution
02Accurate, Independently Validated Portfolio Baseline
- Cost baselines from actual financial data — not estimates — withstand CFO scrutiny through reforecasting
- Independent third-party validation catches the 30–40% of applications missed in self-reported inventories
- Trusted baseline eliminates the “how many apps do we actually have” debate that consumes the first 6 months
- Finance will not release program funding based on savings projections built on unvalidated portfolio data
People & Ownership
03Business Ownership, Not IT Ownership, of Rationalization Decisions
- Programs where business leaders own decisions move 3x faster than IT-driven programs
- Chargeback models making application costs visible create natural rationalization pressure without IT initiating
- Named owners with financial accountability make faster, more definitive decisions than IT PMs without budget authority
- Programs must invest in educating business owners on portfolio economics — never assume they arrive informed
Data & Governance
04Ring-Fenced, Multi-Year Program Funding Secured Upfront
- Programs with confirmed multi-year funding complete 70% more decommissions than annually-funded programs
- Ring-fenced funding protects against budget raids during reforecasting cycles that derail annual approvals
- Blended funding models reduce single-source dependency and survive individual funding disruptions
- Monthly realized savings vs. committed cost reporting maintains approval far better than milestone-only reporting
Process & Execution
05Sequencing That Delivers Early, Visible Wins
- Early wins must be genuinely visible — cost eliminated, systems off, infrastructure reclaimed — not assessments completed
- Quick wins selected for stakeholder resonance as much as financial value — goodwill speeds subsequent approvals
- Monthly published metrics (apps decommissioned, dollars saved, FTE freed) maintain momentum between major milestones
- Programs unable to show tangible results within 6 months consistently lose executive attention before reaching high-value waves
People & Ownership
06Dedicated, Stable, Cross-Functional Program Team
- Blend enterprise architects, business analysts, financial analysts, change managers, and migration engineers
- Cross-functional composition prevents technically correct decisions made without business or financial validation
- Dedicated members — not part-time contributors — maintain the sustained execution pace rationalization requires
- Team continuity preserves knowledge about dependencies, owner relationships, and governance history impossible to reconstruct
Process & Execution
07Hard Decommission Dates Enforced Without Exception
- Applications with confirmed dates decommission 4x more reliably than those with aspirational timelines
- Extension requests handled through formal governance with executive approval — never informally accommodated
- Infrastructure teams only allocate decommission resources to applications with confirmed dates
- Sunset dates in replacement contracts legally bind vendor migration support — contractual obligations drive where governance fails
People & Ownership
08Mature Change Management Embedded From Day One
- Stakeholder resistance patterns identified during discovery and addressed before becoming program blockers
- Communication cadence set at launch: monthly all-stakeholder updates, quarterly business reviews, weekly operational briefings
- User adoption measured as a primary KPI — go-live without adoption metrics leads to parallel running cost overruns
- Change managers with business domain expertise build credibility faster than generic change practitioners
Data & Governance
09Robust Data Strategy Preceding Every Decommission
- Retention schedules formally agreed between IT, Legal, Compliance, and Finance before data migration begins
- Data quality remediation budgeted explicitly — programs assuming clean data encounter 2–3x cost overruns
- Archival retrieval tested by actual business users before shutdown — IT-validated retrieval that fails UAT causes emergency reversals
- Data lineage documented from legacy source through archival destination — required by regulators and auditors
Data & Governance
10Continuous Governance That Outlasts the Program
- Technology Radar and architectural standards updated annually — governance evolves rather than becoming obsolete
- New application approval process enforced permanently — portfolio growth is governed, not assumed acceptable
- Rationalization metrics incorporated into IT leadership performance objectives — governance sustained by accountability
- Board-level Legacy Debt Registry reported annually — visibility prevents the gradual debt accumulation that creates the next crisis
Top 10 Reasons for Failure
Showing 10 of 10 failure reasons
Failure reason · Category
Key observations
People & Ownership
01Executive Sponsorship That Is Nominal, Not Active
- Sponsors stop attending steering committees after Wave 1 — business units immediately detect the reduced commitment
- Sponsor transitions leave programs without accountable executive for 3–6 months — business units exploit the vacuum
- Programs framed as “IT efficiency initiatives” never attract business executive sponsorship needed for decommission decisions
- Sponsorship without budget authority is the most dangerous form — sponsors who can’t protect funding provide false security
Process & Execution
02Underestimated Scope and Overcommitted Timelines
- Timeline compression driven by CFO savings expectations rather than execution capacity is the leading cause of credibility collapse
- Scope underestimation in discovery propagates through every wave, creating compounding schedule pressure
- First wave delivery accuracy predicts overall program success more reliably than any other single factor
- Overpromising to secure funding then underdelivering destroys the organizational trust required for later complex waves
People & Ownership
03Treating Rationalization as a Pure IT Program
- IT-led programs optimize for technical outcomes while missing the business value dimensions that determine real savings
- Business units resist IT-initiated rationalization as technology imposed — the same outcome proposed by a business leader is accepted
- IT programs without Finance co-ownership lose budget battles consistently — CFOs defund programs lacking business value articulation
- “IT modernization” attracts IT resources and business resistance; “business capability optimization” attracts business leadership
Data & Governance
04Insufficient or Unstable Program Funding
- Annual budget cycles lose momentum every Q4 as funding uncertainty paralyzes execution planning
- Contingency stripped during approval leaves zero tolerance for the cost overruns statistically inevitable in migration programs
- Savings reclaimed by Finance before reinvestment destroys the self-funding model bootstrapped programs depend on
- Cost overruns in individual migrations — routinely 2–3x estimates — cascade into wave-level budget crises forcing scope cuts
Process & Execution
05No Hard Decommission Dates or Enforcement Mechanism
- Parallel running without end dates becomes the permanent model — dual costs accumulate indefinitely
- “We’ll retire it after the next release” extends legacy application life by years without formal intervention
- Infrastructure teams never allocate decommission resources without confirmed dates — physical decommission never occurs
- Programs fail at enforcing sunset dates exactly when executive sponsors have disengaged — the two failures compound
Process & Execution
06Dependency Discovery Failures Causing Production Incidents
- A single major outage affecting customer-facing systems can freeze an entire program for months
- Production incidents generate secondhand resistance — uninvolved stakeholders become resistant based on what they heard
- Each incident makes subsequent business owners less willing to approve their own decommissions — resistance compounds
- Recovery from a dependency incident negates all timeline benefits gained by shortcutting discovery in the first place
Data & Governance
07Data and Compliance Blockers Discovered Too Late
- Straightforward data exports become 6-month data quality remediation projects — archival complexity is always underestimated
- Regulatory holds freeze entire waves while legal teams negotiate retention — no advance warning ever given
- Programs without legal/compliance in governance miss systemic blockers affecting entire application categories
- Data gaps post-decommission trigger emergency reinstatement — the most visible and damaging form of program failure
People & Ownership
08Change Management Treated as Communication Only
- Business resistance not tracked as a program risk resurfaces at cutover as production blockers delaying go-live
- One-time pre-go-live training without reinforcement produces adoption rates 40–60% below sustained programs
- Per-application change assessments miss cumulative disruption to user populations absorbing multiple system changes
- Declaring change management complete at go-live consistently sees shadow IT re-emerge within 12 months
Data & Governance
09Vendor and Contract Management Failures
- Legacy vendors use contractual mechanisms to delay transitions — programs without dedicated vendor management cannot counter
- Replacement vendor overpromising during procurement then underdelivering is the most common single-vendor failure pattern
- SI gainshare partners optimize for metrics they control — misaligned incentives produce poor strategic rationalization decisions
- Programs without procurement and legal embedded make commercially naive decisions that recreate new forms of lock-in
People & Ownership
10Loss of Institutional Knowledge Mid-Program
- Knowledge transfer processes that exist on paper but are never enforced leave successors rebuilding context that should have been captured
- Business SMEs from Wave 1 discovery unavailable for Wave 3 execution — organizational priorities have moved on
- Legacy experts who leave after early decommissions cannot support dependency analysis for later connected applications
- Programs treating knowledge management as overhead consistently underperform those investing formally in capture and retention
Top 10 Program Risks
Showing 10 of 10 risks
Risk · Likelihood · Impact
Description & mitigation
Critical impact
Likelihood: High
01Production Outage From Undiscovered Dependencies
- Incomplete dependency mapping causes downstream failures when a legacy system is decommissioned
- A single major outage on a customer-facing system can trigger program suspension lasting 3–6 months
Mitigation
Mandatory network traffic analysis + structured integration interviews + 30-day post-decommission monitoring before declaring retirement complete
Critical impact
Likelihood: Medium
02Regulatory or Legal Action From Improper Data Handling
- Premature data destruction triggers regulatory investigation, fines, and mandatory remediation
- GDPR violations from improper data migration carry fines up to 4% of global annual revenue
Mitigation
Legal and compliance sign-off as mandatory decommission gate + data retention schedule formally agreed before any migration begins
High impact
Likelihood: Medium
03Executive Sponsor Departure Mid-Program
- Loss removes decision authority and organizational protection needed to override business unit resistance
- Average time to establish equivalent sponsorship with a new executive: 3–6 months of relationship building
Mitigation
Dual CIO + CFO sponsorship model + program governance embedded in standing organizational committees not dependent on individual relationships
High impact
Likelihood: Medium
04Budget Withdrawal During Annual Reforecasting
- Annual programs face existential risk every Q3/Q4 when reforecasting pressure cuts discretionary spend
- Programs unable to demonstrate realized savings are disproportionately targeted for reduction
Mitigation
Multi-year ring-fenced funding secured upfront + monthly realized savings reporting to CFO + blended funding model reducing single-source dependency
High impact
Likelihood: Medium
05Mass Business User Rejection of Replacement Platform
- Large-scale rejection after legacy retirement creates operational disruption with no fallback available
- Shadow IT re-emergence recreates portfolio complexity faster than the program eliminated it
Mitigation
Pilot deployments before full migration + parallel running with measured adoption thresholds as cutover gates + sustained post-go-live hypercare
Medium impact
Likelihood: High
06Vendor Lock-In Recreated Through Replacement Platform
- Replacement platforms without exit strategy planning recreate lock-in within 5–7 years
- SaaS platforms with proprietary data models and punitive exit terms are the most common future rationalization debt source
Mitigation
Data portability requirements contractually mandated + open API standards required + exit clauses negotiated upfront in all replacement agreements
Medium impact
Likelihood: High
07Scope Creep Consuming Program Capacity
- Feature parity demands expand migration scope, consuming capacity allocated for subsequent waves
- “While we’re at it” requests convert migration projects into development programs with no decommission outcome
Mitigation
Formal scope change control with ARO approval + feature parity capped at 80% of legacy functionality + enhancements deferred to post-migration roadmap
Medium impact
Likelihood: High
08Key Person Dependency on Legacy System Experts
- Single individuals holding undocumented legacy knowledge create catastrophic risk if they depart before knowledge transfer
- Retention risk increases as systems approach decommission — legacy experts have significant negotiating leverage
Mitigation
Knowledge capture mandatory before decommission proceeds + retention bonuses tied to transfer completion + succession planning for all single points of failure
Critical impact
Likelihood: Medium
09Cybersecurity Incident Targeting Transitioning Systems
- Transitioning systems present the highest attack surface — dual access paths and relaxed controls are primary targets
- Security teams distracted by migration complexity miss vulnerability indicators caught under normal monitoring
Mitigation
Enhanced security monitoring during all transitions + zero-trust controls on both legacy and replacement simultaneously + penetration testing before cutover
High impact
Likelihood: Medium
10Program Delivering Cost Reduction Without Business Capability Improvement
- Programs that decommission apps but fail to improve business capabilities are deemed failures regardless of IT cost savings
- Cost-only outcomes permanently damage IT credibility and make future modernization approvals significantly harder
Mitigation
Business capability outcomes defined alongside cost metrics from inception + value realization reviews at 6 and 12 months + adoption measured as primary KPI
Success Factors, Failure Reasons & Risks — Interactive Plotters
Application Rationalization & Modernization Programs · Three visualisations
Success factors
Failure reasons
Risks
Each axis is a program dimension. Green = success factor coverage. Red = where failure reasons cluster. Amber dashed = risk exposure. Gaps between green and red reveal the most fragile dimensions — sponsorship and hard date enforcement show the widest gap.
Success factor
Failure reason
Bridging approach
Hover a node to see its connections
Success factors (green outer ring) connect to the failure reasons they prevent. Bridging approaches (blue) sit between them as enablers. The sponsorship cluster is the most densely connected — the highest-leverage program variable.
Critical impact
High impact
Medium impact
Hover a bubble to see risk details and mitigation
5×5 risk matrix. X = likelihood, Y = impact. Numbers correspond to the Top 10 risks list. Top-right danger zone: Production outage (#1), Regulatory action (#2), Cybersecurity incident (#9) — all critical-impact items requiring pre-program mitigation.
Conclusion
In this article we looked at the Realities, Challenges, Approaches, Reasons for success and failures and risks involved in a typical large scale application rationalization and migration program