

Introduction
Kubernetes has become the de facto standard for container orchestration, promising scalability, portability, and automation. However, many organizations face significant challenges when adopting Kubernetes, especially when moving from traditional infrastructure or simpler cloud platforms. These challenges are not purely technical; they span skills, culture, operations, governance, and architecture.
One of the most common challenges is complexity. Kubernetes is a powerful but intricate system with many moving parts—pods, services, ingress, networking, storage, RBAC, controllers, and more. For teams new to container orchestration, the learning curve can be steep. Understanding how these components interact, troubleshooting issues, and operating clusters reliably requires deep expertise. Organizations often underestimate this complexity and struggle during initial implementation.
Closely related is the skills gap. Kubernetes requires knowledge across multiple domains: Linux, networking, distributed systems, cloud infrastructure, security, and DevOps practices. Many organizations lack experienced platform engineers and must invest in training or hiring. Without the right expertise, clusters can become unstable, insecure, or inefficient, leading to frustration and loss of confidence in the platform.
Another major challenge is operational overhead. Running Kubernetes is not just about deploying applications; it involves managing cluster upgrades, scaling, monitoring, backup, security patches, and disaster recovery. Platform teams must build and maintain CI/CD pipelines, observability stacks, and governance controls. For organizations without mature DevOps or platform engineering practices, this operational burden can be overwhelming.
Networking and security are also frequent pain points. Kubernetes networking introduces concepts such as service discovery, ingress controllers, network policies, and container networking interfaces (CNI). Integrating Kubernetes with enterprise networks, identity systems, and security controls—such as zero-trust policies, secrets management, and compliance—can be complex. Misconfiguration can expose vulnerabilities or break connectivity, especially in hybrid or regulated environments.
Cultural and organizational factors also play a critical role. Kubernetes adoption often requires a shift toward DevOps and platform engineering, emphasizing automation, shared responsibility, and self-service. Traditional siloed teams—development, operations, and security—may resist this change. Without clear ownership and collaboration, platform initiatives can stall.
Cost management can be another surprise. While Kubernetes enables efficient resource utilization, poorly configured clusters can lead to over-provisioning, idle resources, or complex cost visibility. Organizations must implement autoscaling, rightsizing, and FinOps practices to control expenses effectively.
Finally, tooling and ecosystem choices create decision overload. Kubernetes has a vast ecosystem of tools for networking, service mesh, CI/CD, observability, and security. Selecting, integrating, and maintaining the right stack can be challenging, especially for organizations early in their journey.
One of the approaches for organizations to address these challenges is to approach them collectively and comprehensively by creating a Kubernetes cluster and providing a common set of services, tooling, and management so that teams can focus on their responsibilities. This article is first among a series of blogs discussing the approach
Conceptual Kubernetes Architecture
The following diagram is a conceptual Kubernetes architecture depicting various components. At a high level, Kubernetes architecture consists of a control plane that manages cluster state and scheduling, and worker nodes that run containerized applications, connected through networking, storage, and observability layers
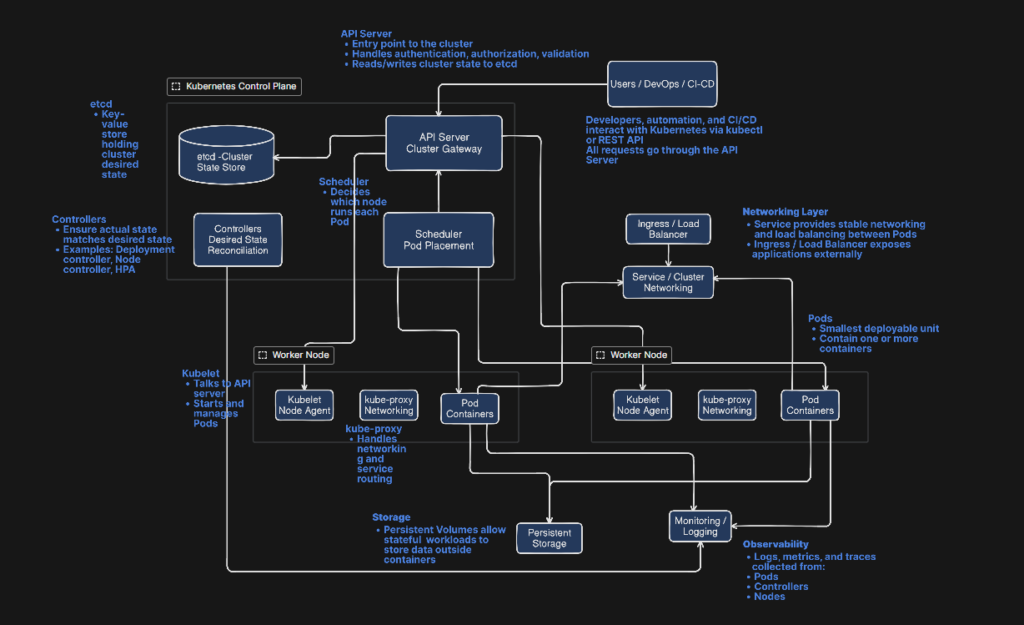
As you can see in the diagram, the control plane consists of the API server (entry point), etcd (cluster state database),Scheduler (places workloads on nodes), and controller manager (maintains desired state), and worker nodes consist of Kubelet (node agent),Container runtime (containerd, CRI-O, etc.), and kube-proxy (networking). Worked nodes is the place where container applications are run. Further, in Kubernetes, the multiple application workloads are separated by Namespace. A namespace is a lightweight organizational and isolation mechanism that enables secure, manageable, and scalable multi-team usage of a Kubernetes cluster. A namespace in Kubernetes is a logical boundary used to organize and isolate resources within a single cluster. It allows multiple teams, applications, or environments (such as dev, test, and prod) to share the same cluster without interfering with each other. Instead of creating separate clusters for every group, namespaces provide soft multi-tenancy inside one cluster. Most Kubernetes objects—like Pods, Deployments, Services, ConfigMaps, and Secrets—are created within a namespace. This means two teams can use the same resource names (for example, a service called web) without conflict, because they exist in different namespaces. Namespaces also enable access control and governance. Using Kubernetes RBAC, administrators can restrict which users or teams can access or modify resources in a specific namespace. They also support resource management through quotas and limits, ensuring one team does not consume excessive CPU, memory, or storage. In addition, namespaces help apply network and security isolation using NetworkPolicies, and they simplify operational practices such as monitoring, logging, and lifecycle management per application group.
Taking a clue from the nature of workloads and the services, the following chart organizes the conceptual framework into shared and app-specific components.
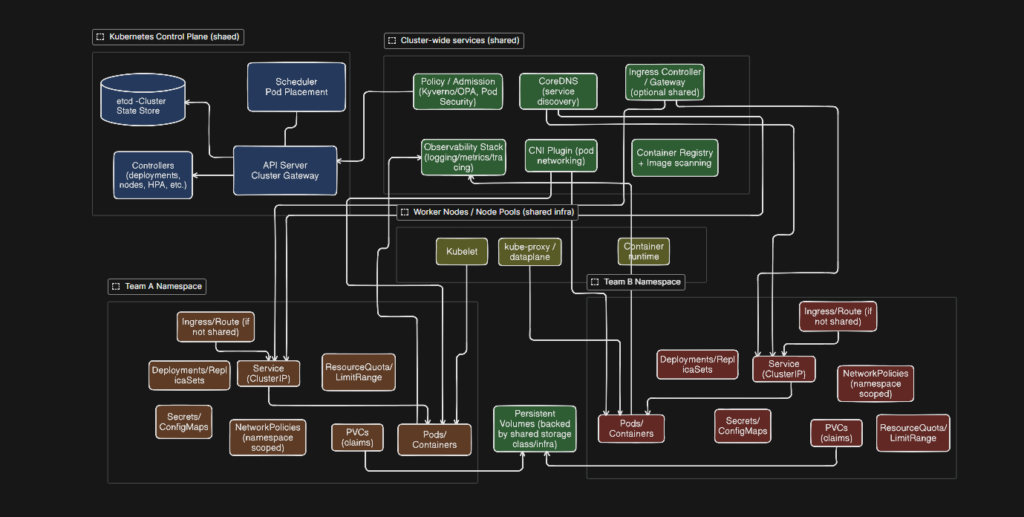
A Minimum Viable Common K8 Cluster
The minimum viable common K8 cluster will be based on the following core principles:
- Self-Service with Guardrails: Teams can deploy independently but within safe boundaries set by the platform team.
- Secure by Default: Security shouldn’t be an afterthought teams need to implement.
- Developer Experience First: If it’s easier to use the platform than work around it, adoption succeeds.
- Observable and Debuggable: Teams need visibility into what’s happening without in-depth Kubernetes knowledge.
- Cost Transparency: Teams should see what they’re consuming and optimize accordingly.
The target model will consist
- One common cluster (initially) with:
- One namespace per team per environment (e.g., team-a-dev, team-a-test, team-a-prod, or separate clusters for prod later)
- Platform-managed shared services in dedicated namespaces (platform-*, observability, security, ingress, etc.)
- Platform team owns:
- Baseline security, networking, observability, and delivery tooling
- App teams own:
- Their workloads, configs, data contracts, SLOs, and on-call for their services
We will create the MVP in a phased manner with
- Tier 1: Essential Services (Deploy First) – These are critical for basic functionality and should be implemented before onboarding any teams. Tier 1 establishes the non-negotiable foundation for running workloads safely and predictably. Start with Identity, Access, and Tenant Isolation so you can separate teams using namespaces, RBAC, and (where needed) network policies and quotas. Next, put in place Ingress, Traffic, and Service-to-Service Networking to standardize how services are exposed externally and how they communicate internally. Add Observability (logging, metrics, tracing) early so issues are visible from day one—typically with centralized logging (EFK/ELK) and metrics/monitoring (Prometheus + Grafana). Finally, consider a Service Mesh (Istio or Linkerd) if you need mTLS, traffic management, and consistent service-to-service controls at scale.
- Identity, Access, and Tenant Isolation
- Ingress, Traffic, and Service-to-Service Networking
- Observability: Logging, Metrics, Tracing
- Centralized Logging (EFK/ELK Stack)
- Metrics and Monitoring (Prometheus + Grafana)
- Service Mesh (Istio or Linkerd)
- Tier 2: Developer Productivity Services: Once the platform is stable, Tier 2 focuses on speed and consistency for teams. Implement CI/CD + GitOps to make deployments repeatable and auditable. Provide a standard Container Registry (Harbor) to manage images, scanning, and promotion across environments. Add Secrets Management using External Secrets Operator integrated with Vault or a cloud secrets manager to reduce secret sprawl and improve security. This tier also formalizes software supply chain security (shift-left scanning plus runtime controls) so teams can move fast without sacrificing safety.
- CI/CD + GitOps Delivery
- Container Registry (Harbor)
- Secrets Management (External Secrets Operator + Vault/AWS Secrets Manager
- Security Supply Chain (Shift-left + runtime)
- Tier 3: Advanced Services: Tier 3 introduces enterprise governance and platform optimization. Add Resource Management + Cost Governance (FinOps, quotas, chargeback/showback) to prevent runaway spend. Implement Backup and Disaster Recovery with tools like Velero for cluster/workload recovery. Enforce guardrails through Policy Enforcement (OPA Gatekeeper or Kyverno) to standardize security and compliance. Finally, offer shared middleware (e.g., managed Kafka, Redis, API gateways, databases) to reduce duplication and accelerate delivery across teams.
- Resource Management + Cost Governance
- Backup and Disaster Recovery (Velero)
- Policy Enforcement (OPA Gatekeeper / Kyverno)
- Shared Middleware
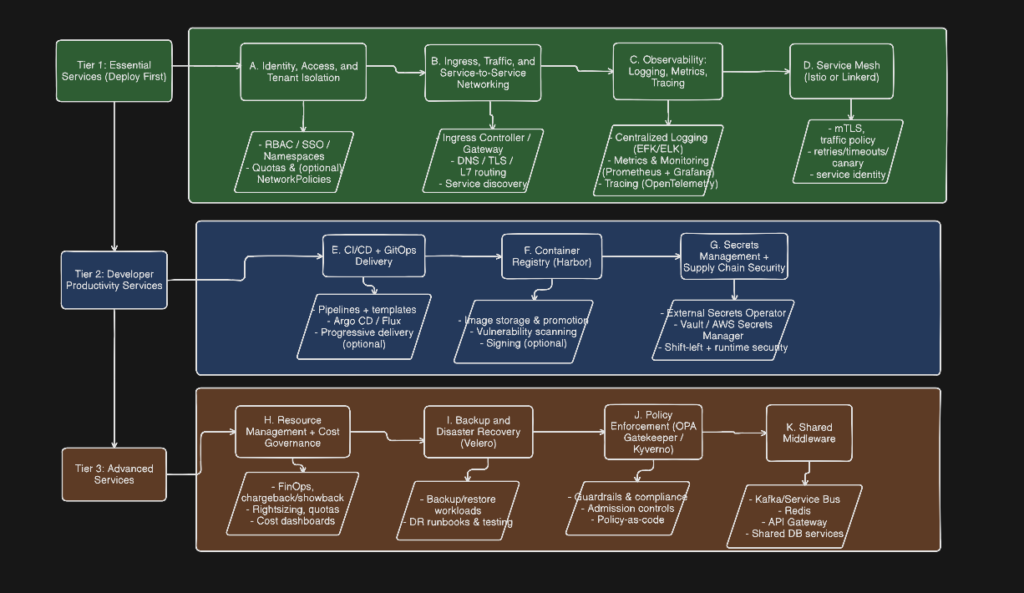
We will discuss each of these tiers in detail separately in different articles